Хорошо известно, что частота шины (FSB) Pentium III составляет 133 МГц, и позволяет передавать 64 бит данных за такт (пропускная способность - 8 байт * 133 млн./с = 1066 Мб/с). Частота шины первых Pentium 4 только 100 МГц и также 64-разрядная, но является "quad-pumped", использует те же принципы работы, что и AGP 4x. Таким образом, шина может передавать 8 байт * 100 млн./с * 4 = 3200 Мб/с. Это очевидно немаленькое улучшение, которое позволяет превзойти процессоры AMD с шиной EV6. На момент выхода Pentium 4 наибольшая частота шины Athlon'ов была 133 МГц, разрядность 64 и шина "double-pumped" (пропускная способность - 8 байт * 133 млн./с * 2 = 2133 Мб/с).
Новая шина Pentium 4 позволяет обмениваться данными с системой быстрее, чем любой другой x86-процессор. Однако самая быстрая процессорная шина не сильно поможет, если память не сможет доставлять данные с соответствующей скоростью. Первый чипсет i850, выпущенный Intel для нового процессора, использует два канала Rambus и, следовательно, дорогостоящую память RDRAM. Эти два канала RDRAM позволяют работать с той же скоростью, что и системная шина Pentium 4 (3200 Мб/с).
|
|
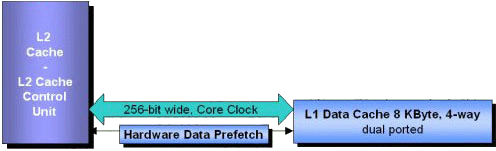
После рассмотрения L2-кэша будет более чем логично перейти к кэшу первого уровня (L1). Pentium III оборудован 16Кб L1-кэша для инструкций и 16 Кб для данных, в Pentium 4 только 8 Кб L1-кэша данных, в то время как кэш трассировки выполнения (Execution Trace Cache) заменяет L1-кэш инструкций Pentium III.
Возможно, Intel уменьшила размер L1-кэш данных до 8 Кб, что составляет половину размера L1-кэша данных в Pentium III и только восьмую (!) часть от кэша Athlon'ов, для того чтобы уменьшить латентность до 2 тактов. В результате латентность чтения, в общем-то, меньше, но небольшой размер L1-кэша данных в Pentium 4 может становиться причиной снижения производительности.
4-х канальный ассоциативный L1-кэш данных Pentium 4 использует 64-байтные каналы. Двухпортовая (dual-port) архитектура позволяет производить одну операцию загрузки и одну сохранения за такт.
Pentium III выпущенный в феврале 1999 года, включает в себя потоковые SIMD расширения. "Потоковая" часть SSE представлена инструкциями предвыборки Pentium III, которые позволяют программному обеспечению загружать данные в кэш, перед тем как они будут затребованы процессорным ядром. Данные инструкции присутствуют и в наборе инструкций Pentium 4, но с новой аппаратной предвыборкой часть из них реализуются автоматически. Это новое устройство способно распознать схему доступа к данным программного обеспечения выполняемого на Pentium 4, таким образом, процессор "предугадывает", какие данные понадобятся и совершает их предвыборку в кэш.
Подобная ситуация хорошо знакома по сложным алгоритмам кэша жестких дисков, и отлично видно как возрастает скорость работы с жестким диском в определенных ситуациях. Аппаратная предвыборка Pentium 4 может значительно ускорить выполнение программ, которые используют большие массивы данных.
|
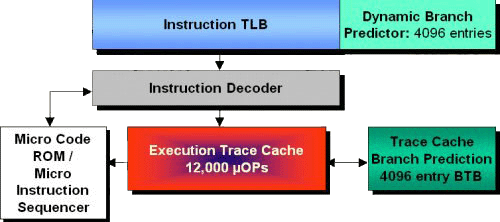
Кэш трассировки выполнения (Execution Trace Cache) Pentium 4 не испытывает вышеописанных проблем. Идея кэша трассировки фактически весьма проста, но для этого требуется больше "кремниевых ресурсов" и конструкторской квалификации, для замещения старого доброго L1-кэша инструкций. По существу, кэш трассировки это ничто иное как L1-кэш инструкций находящийся после декодера.
Как уже было сказано о термине "mOP", это простые инструкции на языке доступном для понимания исполняющими модулями. Они имеют определенный размер и легче для обработки, чем x86-инструкции с переменной длиной. При помощи кэша трассировки Pentium 4 экономит время на перекодирование повторяющихся инструкций и может легче проверить зависимости необходимые для предсказания переходов. Данный кэш гарантирует непрерывную подачу инструкций в конвейер процессора, предохраняя процесс выполнения от возможной угрозы остановки декодирующих модулей. Это особенно важно в связи с высокочастотным дизайном Pentium 4. Кэш трассировки подает на следующую ступень конвейера 3 mOP каждый такт, и, таким образом, обеспечивает такую же скорость как у Athlon'а при идеальных условиях.
В процессоре Pentium III размер mOP составляет 118 бит. Intel не оглашала физический размер кэша трассировки а также размер mOP в Pentium 4. Известно только, что этот кэш может вмещать 12000 mOPs. На основе имеющихся данных можно предположить, что размер кэша трассировки составляет 92-96 Кб. Получается довольно неплохая характеристика, если принимать размер одной mOP в среднем 64 бит.
96 Кб довольно значительный размер и в шесть раз больше, чем 16 Кб L1-кэша инструкций в Pentium III. Учитывая тот факт, что в кэше трассировки сохраняются декодированные x86-инструкции, Pentium 4 осведомлен о том, что фактически делается и требуется. Декодирующие модули, заполняющие кэш обеспечивают только теми mOP, которые фактически будут выполнены.
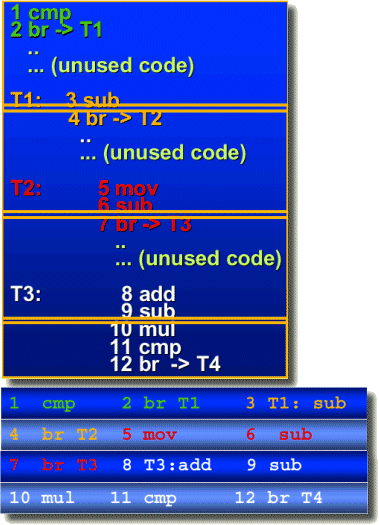
Следующий пример показывает фактический код в верхнем блоке и содержание кэша трассировки
в нижнем. Неиспользуемый код не сохраняется в кэше.
|
Декодеру необходимо процессорное ПЗУ микрокода для формирования иногда довольно длинных последовательностей mOP. В этом случае кэш трассировки не заполняется всеми этими mOP. Как заглушка он только содержит некоторые флаги, сигнализирующие что секвенсор микроинструкций предполагает поддержку чOP для следующей ступени конвейера. Неизвестно как много микроопераций за такт может сформировать секвенсор микроинструкций, но не будет сюрпризом если это количество будет менее 3 mOP за такт, которое кэш трассировки может переслать на следующую ступень конвейера. Это может оказать отрицательное влияние на производительность Pentium 4, который приспособлен для простых инструкций.
Как упоминалось выше, кэш трассировки может значительно улучшить ситуацию в случае с непредсказанным ветвлением. В данной ситуации альтернативный код может быть уже найден в кэше. Чтобы проверки, находится ли уже определенный код в кэше трассировки, есть довольно сложная структура флагов индексирующих блоки кэша.

|

|
Причина более длинного конвейера - желание Intel достижения процессором высочайших тактовых частот. Меньшие ступени конвейера, меньше транзисторов или "затворов", которые им требуются и большая скорость их работы. Однако есть одно большое неудобство при использовании длинных конвейеров. Если в конце конвейера оказывается ветвление, которое не было предсказано, приходится перезаполнять целый конвейер. Чем длиннее конвейер, тем больше "in-flight" инструкций будет потеряно, и больше времени займет, пока конвейер будет заполнен опять.
По заявлению Intel конвейер Pentium 4 может поддерживать до 126 инструкций "на лету" (in-flight), между тем им требуется до 48 операций загрузки и 24 сохранения. Таким образом, улучшенный модуль предсказания переходов, описанный выше, предположительно обеспечивающий заполнение этого конвейера, имеет нечастые возможности.
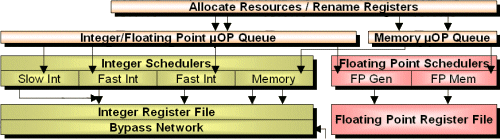
Операции в кэше трассировки, описанные выше, представляют только первых пять ступеней конвейера Pentium 4. Далее следует:
|

|
Несколько другая ситуация получается с инструкциями, которые не могут быть обработаны модулями быстрого выполнения. Эти инструкции или микрооперации могут обрабатываться только "медленным АЛУ", который работает не с двойной скоростью. Большинство инструкций вынуждено использовать этот путь, что, безусловно, звучит пугающе. Однако большая часть кода фактически содержит наиболее простые инструкции (AND, OR, XOR, ADD,...), что делает данную технологию довольно полезной.
Если посмотреть на блоки, представляющие FPU-часть Pentium 4, то увидим ситуацию несколько хуже. При сравнении данной части с блок-схемой Pentium III, можно заметить что Intel фактически урезала некоторые части SSE/MMX. Pentium III использует два MMX и два SSE модуля, а в Pentium 4 их только по одному. Intel утверждает, что добавочные модули не повышают производительности SSE/SSE2, MMX или FPU. Однако результаты некоторых тестов свидетельствуют не в пользу данного заявления.
144 новые инструкции включают, прежде всего, все что есть в SSE. Упакованные 128-битные данные, которые могли быть только в виде четырех значений с плавающей точкой одинарной точности в SSE могут теперь обрабатываться во всех следующих вариантах:
Возможности, несомненно, обширные и небесполезные. Intel надеется, что разработчики программного обеспечения вскоре заменят старые x87-FPU-инструкции на SSE2-инструкции с плавающей точкой двойной точности. AMD заявила также, что ее Hammer-линия x86-64 процессоров будет включать SSE2.
Но, по мнению некоторых аналитиков, есть сомнения, что SSE2 сможет заменить x87-инструкции в научном программном обеспечении. Не следует забывать, что первоначальный FPU использует 80-разрядные значения с плавающей точкой, которые не меньше чем 64-разрядные в SSE2.
| 2. Структурные схемы процессоров | Содержание | 4. Hyper-Threading Technology (Simultaneous Multi-Threading) |